
GenRA Manual: Data Gap Analysis
- Choosing similarity context
- Interpreting the source analogue outcomes
- Physicochemical similarity
- Immediate neighborhood exploration
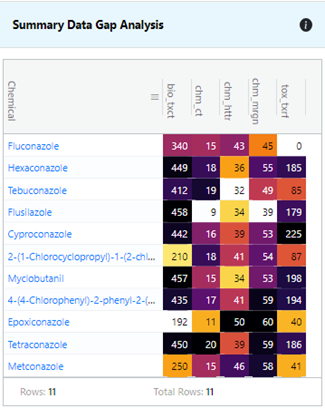
Panel 2: Summary Data Gap Table
Panel 2 provides a summary overview of information available for Fluconazole and its source analogues (Figure 18). The color shade in the displayed table represents a measure of ‘information availability’ for the target and its source analogues across the neighborhood. The information availability is categorized and scaled by type across the neighborhood from light (low) to dark (high). Bio_txct represents the number of HTS assays that a substance has been tested in, whereas tox_txrf represents the number of study-toxicity effects combinations from ToxRefDB. The information availability for the chemical fingerprints represent the number of structural bits present. The numbers will vary across the chemical fingerprints since their length and complexity varies; for example Morgan fingerprints have a bit vector length of 2048 but ToxPrints have 729 possible atom, bond and functional group fragments. In the case of target Fluconazole, there are results for340 HTS assays but there is no in vivo toxicity data available in ToxRefDB.
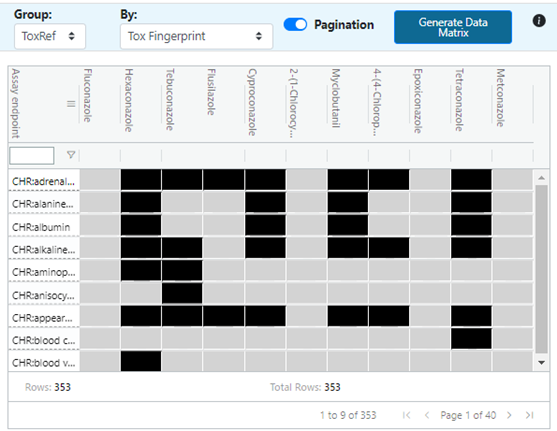
Panel 3: Data Gap Matrix
In Figure 18, the tox_txrf and bio_txct numbers are expanded upon in panel 3, with tox_txrf corresponding with selection of Group: ToxRef (default) and bio_txct corresponding with selection of the ToxCast option. Black boxes here indicate presence of data, or known outcomes, while gray boxes indicate data gaps. Since there are over 300 different study type to toxicity effect combinations represented in ToxRefDB and even more for ToxCastDB, the user can toggle off the paginate option to scroll through the toxicity effects represented or leave it on and click through the pages using the arrows at the bottom of the panel. Note that any studies for which no data at all is present in the source analogues and target will be omitted from the panel 3 matrix. Panels 2 and 3 provide a perspective of data sparsity across the source analogues relative to the target before the data matrix in panel 4 is generated.
Next chapter: Analogue Evaluation